YAMAHA ルーターRTX830
(税込) 送料込み
商品の説明
YAMAHA RTX830
新品未使用
未開封品です
メーカー希望小売価格:83,
発送時は
外箱に入れてお送り致します
IP種類: IPV6
VOIP対応有無: VOIP有
color: GRAY
伝送方式: 有線
有線LAN規格: 1000BASE−TX
#ヤマハ
#YAMAHA商品の情報
| カテゴリー | 家電・スマホ・カメラ > PC/タブレット > PC周辺機器 |
|---|---|
| ブランド | ヤマハ |
| 商品の状態 | 新品、未使用 |

RTX830 特長

Amazon.co.jp: YAMAHA RTX830 ギガアクセスVPNルーター (整備済み品

楽天市場】ヤマハ YAMAHA ギガアクセスVPNルーター RTX830 | 価格比較
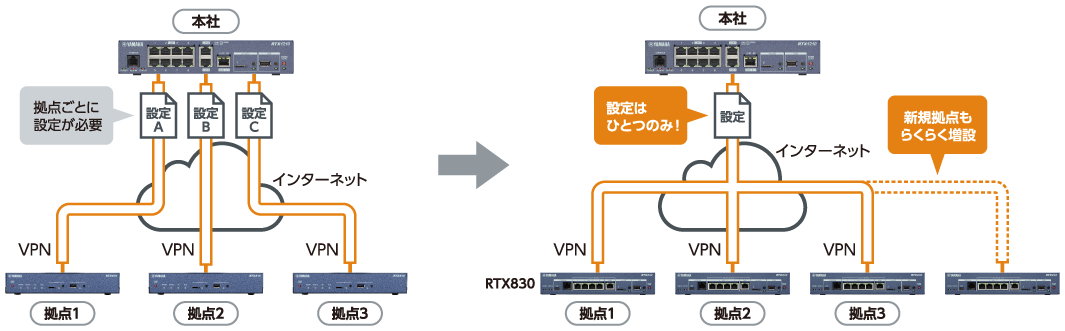
RTX830 特長
中古】YAMAHA ギガアクセスVPNルーター RTX830 : rtx830 : NW工房-中古

楽天市場】ヤマハ YAMAHA ギガアクセスVPNルーター RTX830 | 価格比較

完売 ギガアクセスVPNルーター #YAMAHA/ヤマハ RTX830 No.5 15.02.30

YAMAHA RTX830 ギガアクセス VPN ルーター(ヤマハ) | イミッション

破格値下げ】 YAMAHA ルーター RTX830 ルーター - fishtowndistrict.com

Amazon.co.jp: YAMAHA RTX830 ギガアクセスVPNルーター (整備済み品
RTX830 Yamaha Corporation ギガアクセス VPNルーター Rev.15.02.25

YAMAHA RTX830 ギガアクセス VPNルーター 良質 49.0%割引 www

ヤマハルーター RTX830導入手順例(インターネット接続、ネットボランチ

定番のお歳暮 【中古】YAMAHA RTX830 VPNルーター ルーター

YAMAHA ルーター RTX830 | monsterdog.com.br

RTX830 特長

2022新発 0029◇ 新F △Ω 保証有 初期化済・祝10000!取引突破!! ギガ

YAMAHA ルーター RTX830 | monsterdog.com.br

YAMAHAルーターの交換作業 | GLANCE Co., Ltd.

ヤマハルーター RTX830 2台 『1年保証』 家電・スマホ・カメラ | bca

楽天市場】【中古】 ヤマハ ルーター RTX830 通電確認済み 送料 無料

YAMAHA ギガアクセスVPNルーター RTX830 - nomangue.com.br

ヤマハ ギガアクセスVPNルーター RTX830 モバイルルーター | www

売り切りセール】YAMAHA ギガアクセスVPNルーター RTX830
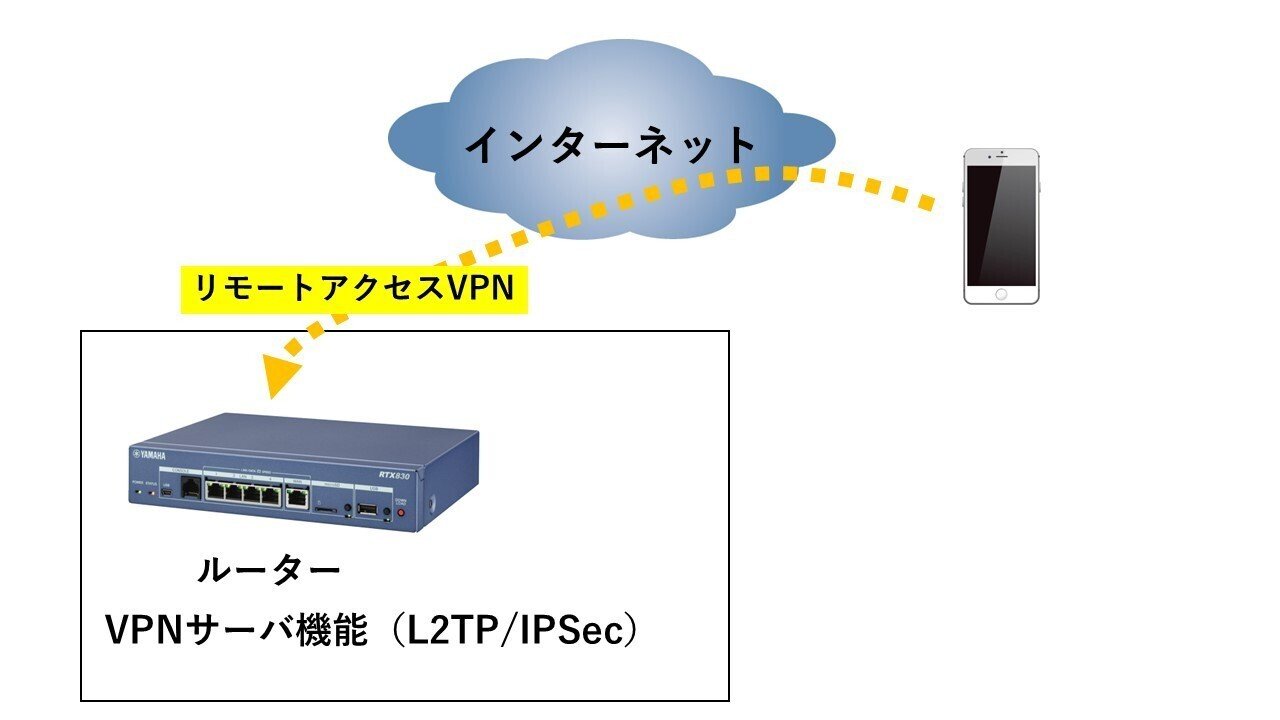
ヤマハルーター RTX830 IKEv2リモートアクセスVPN設定手順(config例

ヤマハ - YAMAHA製 ギガアクセスVPNルーター RTX830の通販 by 株式会社

RTX830 YAMAHA ギガアクセスVPNルーター ヤマハ 65%OFF【送料無料

予約販売】本 YAMAHA ルーター RTX830 未使用LANケーブル5m9本セット

在庫有】 YAMAHA RTX830ギガアクセスVPNルーター PC周辺機器

YAMAHA ギガアクセスVPNル-ター RTX830 ヤマハ 小規模拠点向

ヤマハルーター リモートアクセスVPN設定手順(RTX830)

YAMAHA-VPNルータRTX1210とRTX830は何がどう違う??【人気機種を徹底

楽天市場】【現行品】【送料無料】 YAMAHA / ヤマハ RTX830 ギガ

新品 未使用 YAMAHA RTX830 ヤマハ ギガアクセスVPNルーター

ヤマハ ギガアクセスVPNルーター RTX830 買取実績 | IT機器の買取実績

ヤマハルーター パスワード初期設定手順(Web設定画面)|IP実践道場
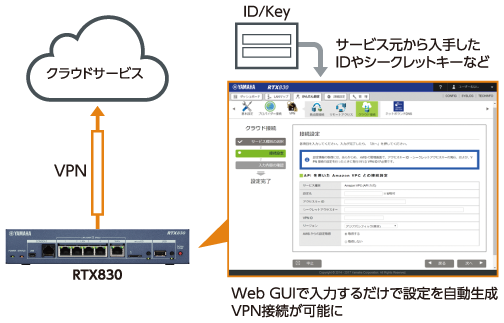
RTX830 特長

ヤマハ ギガアクセスVPNルーター「RTX830」のVPN対地数などの機能拡張

ルーター:YAMAHA RTX830 No.3 | 株式会社アトラックNEO

破格値下げ】 Ω x1# 領収書発行可能・祝10000取引! ギガアクセスVPN



商品の情報
メルカリ安心への取り組み
お金は事務局に支払われ、評価後に振り込まれます
出品者
スピード発送
この出品者は平均24時間以内に発送しています














